发布日期:2025-04-07 03:59 点击次数:107

炒股就看金麒麟分析师研报,巨擘,专科世博体育(中国)官方网站,实时,全面,助您挖掘后劲主题契机!
开端:量子位
AI不外周末,硅谷亦然如斯。
大周日的,Llama眷属上新,一群LIama 4就这样倏得发布了。
这是Meta首个基于MoE架构模子系列,现时共有三个款:
Llama 4 Scout、Llama 4 Maverick、Llama 4 Behemoth。
临了一个尚未推出,只是预报,但Meta照旧侃侃谔谔地称前两者是“咱们迄今为止起初进的型号,亦然同类居品中最佳的多模态型号”。
详备来看一些关键词——
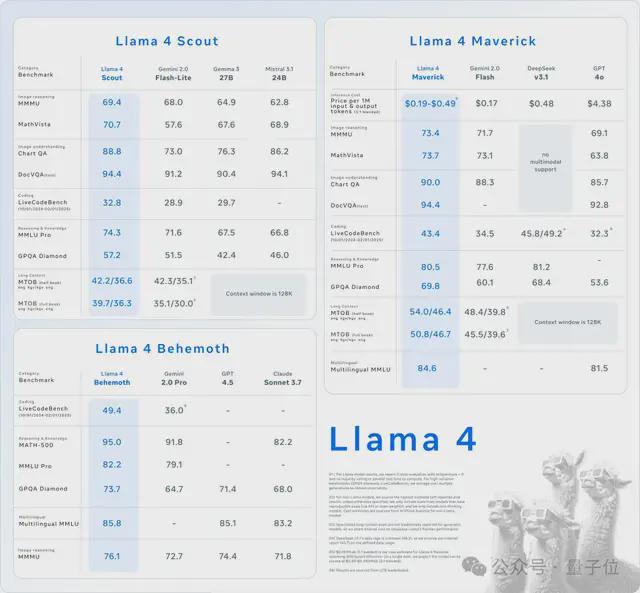
Llama 4 Scout,16位大师的170亿激活参数的多模态模子,单个H100 GPU可运行, 同类SOTA,并领有10M崎岖文窗口
Llama 4 Maverick,128位大师的170亿激活参数多模态模子,打败GPT-4o和Gemini 2.0 Flash,与DeepSeek-V3同等代码智商参数只消一半,主打与DeepSeek相似的性价比,单个H100主机即可运行。
Llama 4 Behemoth:2万亿参数的超大超强模子,以上二者皆由这个模子蒸馏而来;现时还在测验中;多个基准测试高出GPT-4.5、Claude Sonnet 3.7和 Gemini 2.0 Pro。
Meta官推厚谊默示,这些Llama 4模子标志着Llama生态系统新期间——原生多模态AI创新的动手。

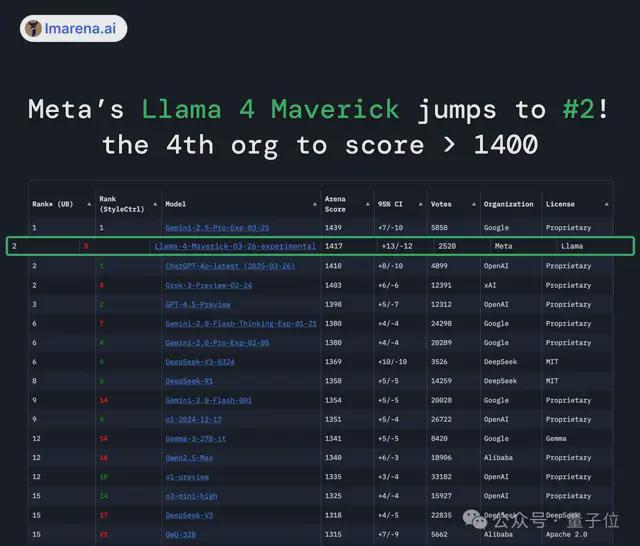
与此同期,大模子竞技场名次迎来一轮更新。
这次发布的Llama 4 Maverick,在贫苦指示、编码、数学、创意写稿方面比肩第一;得分1417,不仅大大超过了此前Meta自家的Llama-3-405B(耕种了149分),还成为史上第4个打破1400分的模子;。
况兼跑分明确——超过DeepSeek-V3,罢了亮相即登顶,径直成为名纪律一的开源模子。
谷歌CEO劈柴哥第一时候发来贺电:
中杯、大杯首批亮相
了解了Llama 4眷属全体成员后,咱们先来眼光一下首批发布的2个模子:
两者均已能在Llama官网和抱抱脸崎岖载。

咱们抓取并索求出这俩模子的一些秉性:
Meta首批MoE架构模子
这是Llama系列,第一批使用MoE(搀和大师模子)构建的模子。
中杯Llama 4 Scout有17B激活参数,领有16个大师模子。
大杯Llama 4 Maverick领有17B激活参数,领有128个大师模子。
至于还没和大家安靖碰面的超大杯Llama 4 Maverick,领有288B激活参数,领有16个大师模子。
相配长————的崎岖文
Llama 4系列,均具有很长的崎岖文窗口。
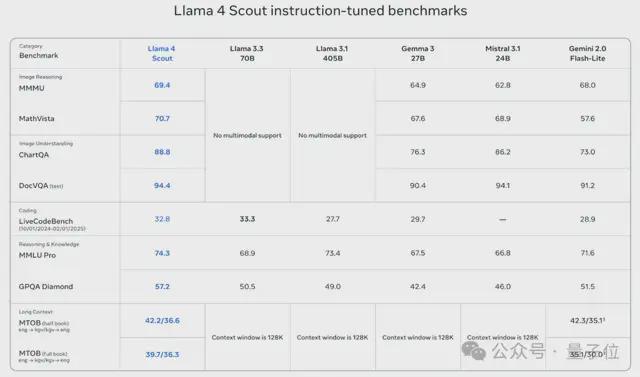
这少量主要体现时Meta公布的中杯Llama 4 Scout的详备数据里:
这个成立,让它在等闲的测评集上,比Gemma 3、Gemini 2.0 Flash-Lite和Mistral 3.1的收尾更优秀。

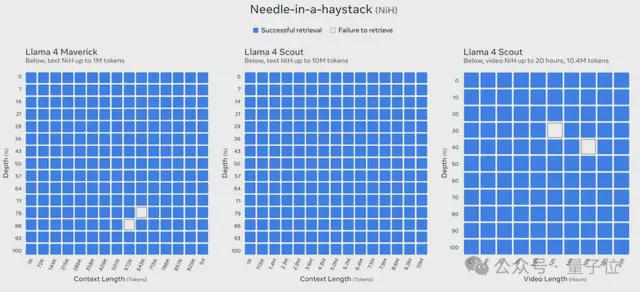
它在‘大海捞针’测试上的阐述如下:

收尾如下:
那么之前的Llama系列模子的崎岖文窗口情况呢?
Meta官方博客中是这样写的:
原生多模态想象
Llama 4系列,开启了Llama的原生多模态期间。
云尔经公开对外的中杯和大杯,被官方称为“轻量级原生多模态模子”。
给用户的体验便是,上传一张图片,不错径直在对话框中发问对于这张图片的各式问题。
不是我说,Llama终于长眼睛了!!!

上头这张动图展示的只是是最基础的,“为难”程皆升级也不怕。
比如喂它一张铺满用具的图片,问它哪些相宜来干某个活。
它会很快地把适用的用具圈出来:

要认心情+认小鸟,也没在怕的:

中杯和大杯皆在官方先容中被打上了“宇宙上同类居品中最佳的多模态模子”的tag。
来看和Llama系列前作、Gemma 3、Mistral 3.1、Gemini 2.0 Flash-Lite的对比收尾——
不错看到,在各个测评集上的阐述,Llama 4 Scout样样皆是新SOTA。
话语资质Max
经过了预测验和微调的Llama 4,掌持全球12种话语,以此“便捷全球开发者的部署”。

比DeepSeek更狠的“AI模子拼多多”
一定要跟大家分享的一个细节,Meta这次在模子API价钱方面,下狠手了!
先说收尾:
系列超大杯Llama 4 Maverick,不仅超过了同类型号其它模子,价钱还相配之鲜艳。
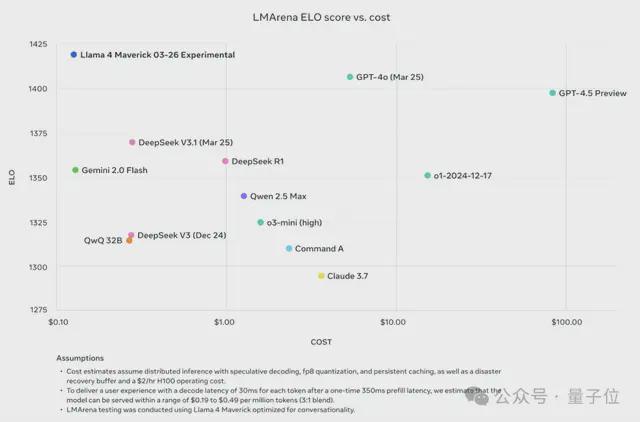
更直不雅地来看这张表格,简直狠过DeepSeek——从性能到价钱各个纬度。

要知说念,超大杯Llama 4 Behemoth属于是Llama 4系列的进修模子。
若是说中杯和大杯是轻量级选手,这位便是全皆的重磅玩家。
288B激活参数,16个大师模子。
最进攻的是,它的总参数目高达2000B!
在数学、多话语和图像基准测试中,它提供了非推理模子的起初进性能。
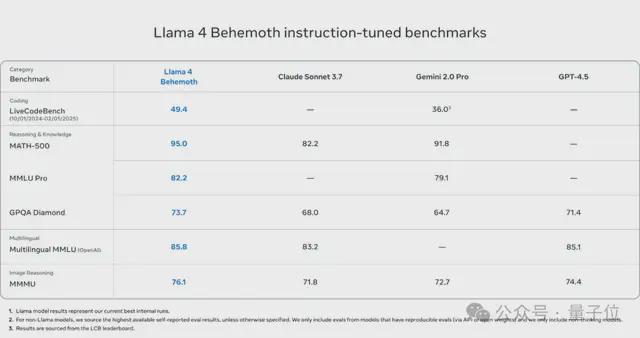
当“最牛”和“最低廉”摆在一说念的时候,试问哪位开发者会不心动?(doge)
测验细节
用他们我方的话来说,Llama系列是进行了绝对的再行想象。现时第一组LIama 4系列模子,他们也公布了具体的测验细节。
预测验
他们初度使用搀和大师MoE架构,在MoE架构中,单个token仅激活总参数的一小部分。MoE架构在测验和推理方面具有更高的推测效果,固定测验FLOP资本情况下质地更高。
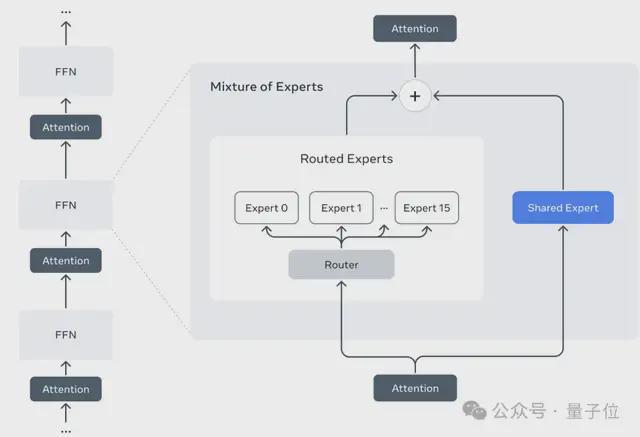
比如,Llama 4Maverick模子有17B个激活参数和400B个总参数。他们使用轮换的密集层和搀和大师(MoE)层来提高推理效果。
MoE层使用128位路由(Routed)大师和一位分享大师。每个令牌皆会发送给分享大师以及128位路由(Routed)大师之一。
因此,诚然通盘参数皆存储在内存中,但在为这些模子提供管事时,唯有总参数的子集被激活。
这通过裁汰模子管事资本和延伸来提高推理效果——Llama 4 Maverick 不错在单个H100 DGX主机上运行,以便于部署,也不错通过漫衍式推理罢了最高效果。
他们早期和会,将文本和视觉token无缝集成到长入模子中。
他们开发了一种新的测验工夫:MetaP,不错蛊卦关键模子超参数,比如每层的学习率和驱动化模范。
收尾发现,所选的超参数能在批量大小、模子宽度、深度和测验token的不同值之间很好地蔓延和泛化——
Llama 4通过在200种话语(包括100多种话语,每种话语有高出10亿个词库)上进行预测验,罢了了开源微调责任,多话语词库总量是Llama 3的10倍。
此外,他们使用FP8精度进行高效模子测验,同期不甩掉质地并确保模子 FLOPs的高欺骗率—在使用FP8和32K GPU 预测验 Llama 4 Behemoth模子时,收尾他们罢了了390TFLOPs/GPU。
用于测验的举座搀和数据包括30多万亿个token,是Llama 3预测验搀和物的两倍多,其中包括各式文本、图像和视频数据集。
在所谓的“中期测验”中连接测验模子,通过新的测验规律(包括使用专科数据集进行长崎岖文蔓延)来提高模子的中枢功能。
后测验
后测验阶段,他们提议一个课程战略,与单个步地大师模子比拟,该战略不会甩掉性能。
在Llama 4中,接受了一种不同的规律来立异咱们的后期测验管说念:
轻量级监督微调(SFT)>在线强化学习(RL)>轻量级径直偏好优化 (DPO)。
一个关键的教学是,SFT和DPO可能会过度拘谨模子,截止在线强化学习阶段的探索,并导致精度裁汰,尤其是在推理、编码和数学鸿沟。
为了处理这个问题,他们使用Llama模子行动评判范例,删除了50%以上被标识为浮浅的数据,并对剩余的较难数据集进行了轻量级SFT处理。
在随后的在线强化学习阶段,通过仔细聘用较难的指示,咱们罢了了性能上的飞跃。
此外,他们还实行了一种一语气的在线强化学习战略,即轮换测验模子,然后欺骗模子不休过滤并只保留中等难度到较高难度的指示。事实诠释注解,这种战略在推测量和准确性的量度方面相配成心。
然后,他们接受轻量级DPO来处理与模子反应质地揣度的拐角情况,从而灵验地在模子的智能性和对话智商之间罢了了精采的均衡。活水线架构和带有自顺应数据过滤功能的一语气在线RL战略,临了训导了现时的LIama 4。
转头来看,Llama 4架构的一项关键创新是使用交错属办法层,而无需位置镶嵌。此外,他们还接受了属办法推理时候温度缩放来增强长度泛化。
这些他们称之为iRoPE架构,其中“i”代表 “交错 ”属办法层,凸起了支援 “无穷”崎岖文长度的永久想象,而 “RoPE ”指的是大大量层中接受的旋转位置镶嵌。
Llama 4 Behemoth
临了,他们还露馅了超大模子Llama 4 Behemoth一些蒸馏和测验细节。
咱们开发了一种新颖的蒸馏亏空函数,可通过测验动态加权软想象和硬想象。
预测验阶段,Llama 4 Behemoth的代码蒸馏功能不错摊销学生测验中使用的大部分测验数据推测蒸馏想象所需的资源密集型前向传递的推测资本。对于纳入学生测验的其他新数据,他们在Behemoth模子上运行前向传递,以创建蒸馏想象。
后测验阶段,为了最大限制地提高性能,他们删减了95%的SFT数据,而袖珍模子只需删减50%的数据,以罢了对证地和效果的必要和蔼。
他们在进行轻量级SFT后,再进行大范畴强化学习(RL),模子的推理和编码智商会有更权贵的提高。
强化学习规律侧重于通过对战略模子进行pass@k分析来抽取高难度指示,并凭据指示难度的增多经心想象测验课程。
此外还发现,在测验历程中动态过滤掉上风为零的指示语,并构建包含多种智商的搀和指示语的测验批次,有助于提高数学、推理和编码的性能。临了,从各式系统指示中取样对于确保模子在推理和编码方面保持指示奴婢智商并在各式任务中阐述出色至关进攻。
由于其范畴空前,要为两万亿个参数模子蔓延RL,还需要立异底层RL基础门径。
他们优化了MoE并行化的想象,从而加速了迭代速率;并开发了一个完全异步的在线RL测验框架,提高了天真性。
现存的漫衍式测验框架会甩掉推测内存以将通盘模子堆叠在内存中,比拟之下,他们新基础架构八成将不同模子天真分派到不同GPU上,并凭据推测速率在多个模子之间均衡资源。
与前几代居品比拟,这一创新使测验效果提高了约10倍。
One More Thing
要知说念,由于昨天DeepSeek发了新论文,搞得奥特曼皆坐不住了,迅速出来发声:
但,谁知说念中途又杀出个Llama 4?!
前有猛虎,后有虎豹,OpenAI你简直得加油了……
网友捉弄说念,当奥特曼一睁眼,看到Llama 4来了,况兼Llama 4的资本比GPT-4.5裁汰了3个数目级后——
他的情状一定是酱婶儿的:

以及比拟Llama,现时可能高明低调的DeepSeek,可能不知说念什么时候倏得就会推出DeepSeek R2和V4…同在杭州的通义千问也劲头十足,Llama也好GPT也好,基本成为平行参考了。
太平洋这头,照旧动手落地应用和智能体了。
参考联接:
[1]https://www.llama.com/
[2]https://ai.meta.com/blog/llama-4-multimodal-intelligence/
[3]https://x.com/AIatMeta/status/1908598456144531660
[4]https://x.com/lmarena_ai/status/1908601011989782976
[5]https://x.com/IOHK_Charles/status/1908635624036590070
新浪声明:此音尘系转载改过浪联结媒体,新浪网登载此文出于传递更多信息之主见,并不虞味着赞同其不雅点或说明其描摹。著述本体仅供参考,不组成投资建议。投资者据此操作,风险自担。 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负剪辑:凌辰 世博体育(中国)官方网站